前言
系列文章
遍历字符串文字不连续
当从UITextView读取attributedText后,如果执行enumerateAttributes方法遍历,会出现unicode、中英文字符分开获取到的情况
示例
1 | let attributeString = NSMutableAttributedString(string: "🔴🔴哈哈哈哈哈哈www.baidu.com", attributes: [.font : UIFont.systemFont(ofSize: 14)]) |
运行结果
1 | 🔴🔴{ |
由运行结果可以看出,在我们进行遍历时,获取到的range是按照Unicode、中英文来断开的,正常情况这是没有什么影响的,但是对于文本编辑来说,因为有链接、普通文字、at等情况,所以需要将enumerate中属性相同的string拼接到一起。大概思路就是利用attribute来判断substring是否属于同一数据段,具体做法请看接下来介绍的富文本的选择、删除处理。
富文本选择、删除处理
需求介绍
在富文本编辑中,经常做的是链接、@信息、普通文本等编辑,这些类型当中,通常只有普通文本支持单字选择与删除,而链接与@信息的话一般是只能进行整体删除和选择(不能从segment中间开始选择)。
上文介绍到,当我们遍历从UITextView中获取到的富文本时,获取到的字符串并不是连续的,但是呢,我们的需求需要将相邻的相同的数据合并到一起。那我们根据什么条件来判断是否相邻的字符串是否是相同segment呢?有以下两个条件:
- range连续
- attribute相同
只要同时满足上诉两个条件,就可以认为是属于相同segment,应该合并到一起。
选择
效果:

先上选择的代码:
1 | func fixSelectRange(_ attributeString: NSAttributedString, targetRange: NSRange) -> NSRange { |
逻辑其实挺简单的,如果fixRange的location在获取atRange中,即:
1 | fixRange.location >= atRange.location && fixRange.location + fixRange.length <= atRange.location + atRange.length |
如果当前的attribute是text的话,就不需要进行修改
1 | if attribute.type == .text { |
如果不是文本的话,那么退出条件为:
1 | prevAttribute != nil && !prevAttribute.isEqual(attribute) |
删除
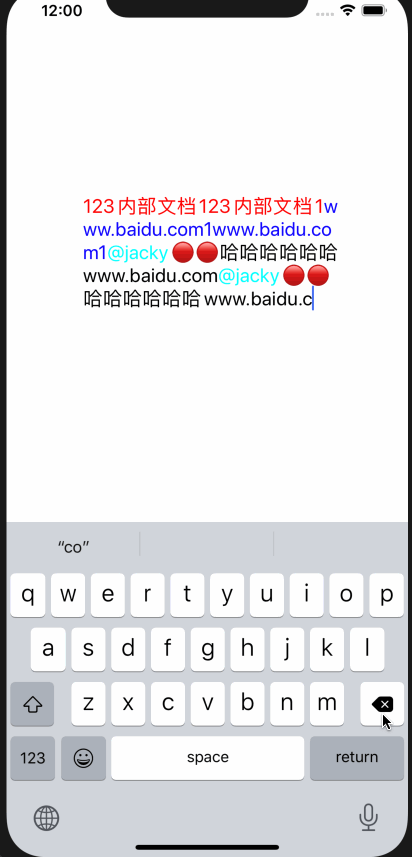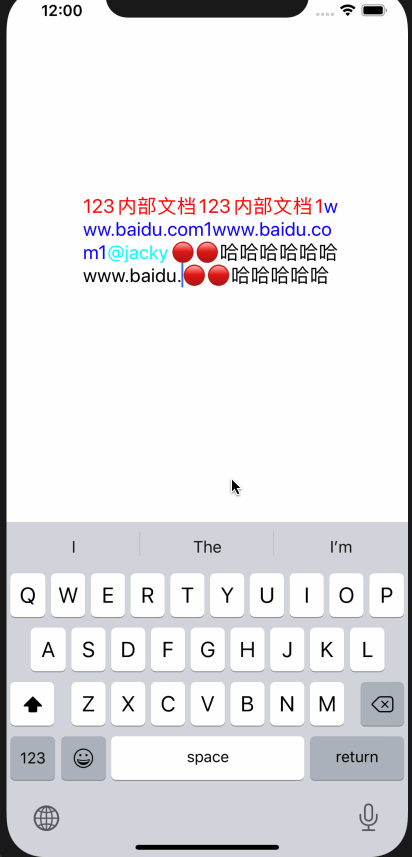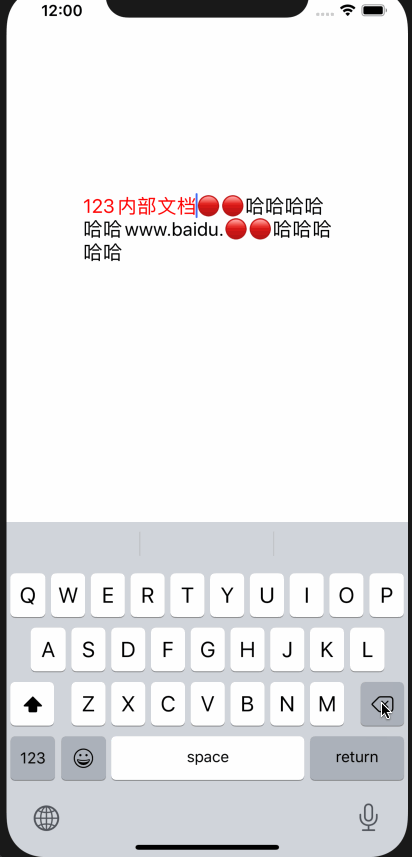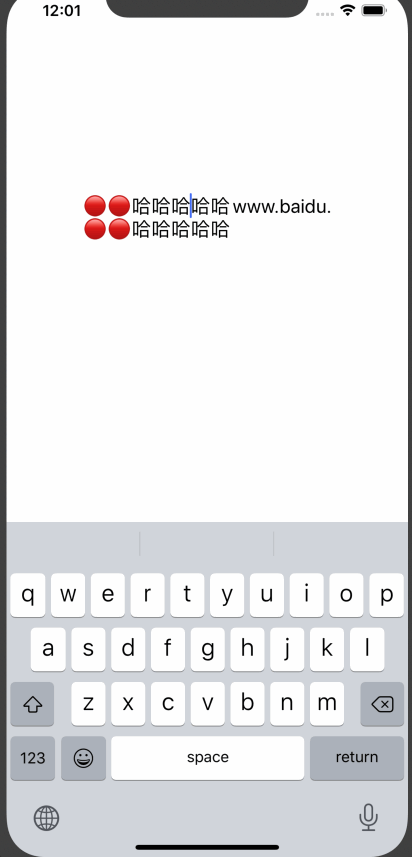
删除与选择不同,选择的话只需要将location移动到segment前即可,删除的话 ,需要将整个segment删掉
效果
代码
1 | func fixDeleteRange(_ attributeString: NSAttributedString, targetRange: NSRange) -> NSRange { |
原理:
逆序遍历attributes,将连续的attributes的range拼接起来,如果targetRange在currentMaxRange中并且不是text类型时,应该删除maxRange,否则直接删除targetRange
结语
以上就是富文本的选择删除处理了,你可以在这里下载demo,如果觉得对你有帮助的话,可以点一下star哦,thks